Parametric v/s Non-Parametric Models
Introduction
We used linear regression for regression problems and logistic regression for classification problems. Decision Trees can handle both problems.
Machine learning can be described as the construction of a function, f, that maps input variables (x) to output variables (y): y = f(x).
The job of an ML Engineer is to find the best mathematical model for the function.
Unlike linear or logistic regressions, decision tree algorithms do not have any assumptions.
PARAMETRIC MODELS
- These models make strong assumptions about the form of the mapping function.
- Very simple and interpretable.
- The set of parameters does not depend upon the amount of data.
- A learning model that summarizes data with a set of parameters of fixed size
(independent of the number of training examples) is called a parametric model.
Source: (Book) Artificial Intelligence: A Modern Approach.
Working Steps of Parametric Models:
- Select a form for the function.
- Learn the coefficient/parameters for the function from the training data.
Benefits:
- Simpler: Easier to understand and interpret results.
- Fast: Very fast to learn from data.
- Less Data: Do not require as much training data and can work well even if the fit to the data is not perfect.
Limitations:
- Constrained: Highly constrained to the specified form.
- Limited Complexity: More suited to simpler problems.
- Poor Fit: Unlikely to match the exact underlying mapping function.
NON-PARAMETRIC MODELS
- These algorithms do not make strong assumptions about the form of the mapping function.
- They are free to form any functional form from the data.
- Non-parametric methods are good when you have a lot of data and no prior knowledge and
when you don’t want to worry too much about choosing the right features.
Source: (Book) Artificial Intelligence: A Modern Approach. - They best fit the training data in constructing the mapping function while maintaining some flexibility to generalize to unseen data.
Benefits:
- Flexibility: Capable of fitting a large number of functional forms.
- Power: No assumptions or weak assumptions about the underlying function.
- Performance: Can result in higher performance models for prediction.
Limitations:
- More Data: Require a lot more training data to estimate the mapping function.
- Slower: Slower to train as they often have far more parameters.
- Overfitting: Higher risk of overfitting the training data and harder to explain why specific predictions are made.
| Aspect | Parametric Models | Non-Parametric Models |
|---|---|---|
| Assumptions | Make strong assumptions about the data distribution. | Do not assume a specific data distribution. |
| Flexibility | Limited flexibility due to predefined assumptions. | Highly flexible, capable of capturing complex patterns. |
| Data Requirement | Requires less data to train effectively. | Needs a large amount of training data. |
| Interpretability | Easy to interpret and explain. | Harder to interpret due to complex structures. |
| Training Time | Faster to train. | Slower to train due to high complexity. |
| Overfitting | Lower risk of overfitting. | Higher risk of overfitting. |
| Example Models | Linear Regression, Logistic Regression, Naive Bayes. | Decision Trees, k-NN, Random Forest, Neural Networks. |
Working of Decision Trees
Decision Trees
- Every time we split the dataset based on some condition/decision, we get a decision tree.
- We tend to separate all the positive classes from negative classes using a decision tree.
- In an ideal case, we find a feature that can split the dataset into pure nodes.
- A pure node is one in which all the data points exhibit the desired behavior or belong to the same class.
- The objective of decision trees is to have pure nodes.
- A decision tree with pure nodes is good at segregating data into respective classes.
- A decision tree can have multiple splits.
- Purity of nodes helps to decide how splitting should be done.
Terminology
- Root Node: Represents the entire population or dataset.
- Splitting: Process of dividing a node into two or more sub-nodes.
- Decision Node: When a sub-node is divided into further sub-nodes, the original sub-node is called a decision node.
- Leaf/Terminal Node: A node that does not split any further.
- Branch/Sub-tree: A subsection of the entire tree.
- Parent Node: A node that is divided into sub-nodes.
- Child Node: A sub-node derived from a parent node.
- Depth of the Tree: The length of the longest path from the root node to the leaf node.
- The root node has a depth of 0.
Types of Decision Trees
Types of Decision Trees
- Classification Decision Tree:
- Used when the target variable is categorical in nature (e.g., Yes/No, Spam/Not Spam).
- It classifies data points into predefined categories based on feature conditions.
- The decision boundaries formed by classification trees are often stepwise and may not always be smooth.
- Common use cases include spam detection, loan approval, and medical diagnosis.
- Regression Decision Tree:
- Used when the target variable is continuous in nature (e.g., predicting house prices, temperature, or sales revenue).
- Instead of predicting distinct categories, it predicts real-valued outputs by computing the mean of observations in a region.
- The splits in the tree aim to minimize variance within each partition of data.
- Common use cases include stock price forecasting, customer spending predictions, and demand estimation.
- Key Differences:
- Classification trees predict labels, whereas regression trees predict numeric values.
- Loss functions differ: classification trees often use Gini impurity or entropy, while regression trees use mean squared error (MSE).
- Regression trees can model complex relationships but are prone to overfitting, requiring pruning or regularization.
Splitting Criteria of Tree Nodes
Gini Impurity
Gini impurity measures the impurity of nodes.
\(\text{Gini impurity} = 1 - \text{Gini}\)
Gini is the probability that two elements chosen randomly from a population are of the same class.
- For a pure node, \( Gini = 1 \)
- Range of Gini is from 0 to 1
Properties of Gini Impurity:
- Helps in deciding the best split
- Lower the Gini impurity, higher will be the homogeneity of the nodes
- Works only with categorical variables
- Performs binary splits only
- Lower the Gini impurity → higher the purity of nodes → higher the homogeneity of nodes
Calculating Gini Impurity:
- Calculate Gini impurity for sub-nodes: \[ \text{Gini impurity} = 1 - \sum_{i=1}^{n} p_i^2 \] where \( p_i^2 \) is the probability of any two random data points belonging to class \( i \).
- Calculate the Gini impurity for the split: \[ \text{Weighted Gini impurity} = (\text{weight of the node}) \times (\text{Gini impurity}) \] The split producing the minimum Gini impurity is selected as the first split.
Information Gain
Information gain is the information needed to describe the parent node minus the information needed to describe the children nodes.
More homogeneous nodes result in higher information gain.
\(\text{IG} = 1 - \text{Entropy (sub-nodes)}\)
Entropy Calculation:
\[ \text{Entropy} = -P_1 \log P_1 - P_2 \log P_2 - P_3 \log P_3 - ... - P_n \log P_n \] where \( P_1, P_2, P_3, ..., P_n \) are the proportions of each class in the node, and the base of the logarithm is \( n \).Steps to Calculate Entropy for a Split:
- Calculate entropy of parent nodes
- Calculate entropy of each child node
- Compute the weighted average entropy of the split
- If the weighted entropy of the child node is greater than the parent node, ignore the split
Decision Tree Regressor
Since information gain and Gini impurity cannot be applied to continuous variables, we use variance reduction.
Variance Calculation:
\[ \text{Variance} = \frac{\sum_{i=1}^{n} (x_i - \mu)^2}{n} \] where \( x_i \) is a data point, \( \mu \) is the mean, and \( n \) is the number of samples.Steps to Calculate Variance for a Split:
- Calculate variance of each child node using the standard formula.
- Calculate the variance of the split as the weighted average variance of each child split.
Note: Applicable only on continuous variables.
Implementation
Initiation
he data we are using is the same as used in the logistic regression modelling. Target variable is still the ‘churn’ variable. We used the Decision Tree Classifier class of tree module of Sklearn library.
from sklearn.tree import DecisionTreeClassifier as DTC
classifier = DTC(class_weight='balanced')
# classifier = DTC()classifier.fit(X_train, y_train)
predicted_values = classifier.predict(X_train)predicted_values[:30]array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 1, 0], dtype=int64)
It is clearly visible from the classification reports that when used on training data the model shows a perfect score of 1 but when the same model is used on test data the metrics drops significantly. This is due to Overfitting of model.
The classifier model tries to learn each and every data from the training set but suffers radically when it comes to applying it on the test set.
#classification report
from sklearn.metrics import classification_report
print(classification_report(y_train, predicted_values))| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 1.00 | 1.00 | 1.00 | 14234 |
| 1 | 1.00 | 1.00 | 1.00 | 3419 |
| Accuracy | 1.00 | 17653 | ||
| Macro Avg | 1.00 | 1.00 | 1.00 | 17653 |
| Weighted Avg | 1.00 | 1.00 | 1.00 | 17653 |
predicted_values = classifier.predict(X_test)
print(classification_report(y_test, predicted_values))| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.86 | 0.87 | 0.86 | 3559 |
| 1 | 0.42 | 0.40 | 0.41 | 855 |
| Accuracy | 0.78 | 4414 | ||
| Macro Avg | 0.64 | 0.63 | 0.64 | 4414 |
| Weighted Avg | 0.77 | 0.78 | 0.77 | 4414 |
Due to the memorizing nature of the classifier instance the model shows perfect score in training classification reports but a significantly low score in testing classification report.
If the model is performing too well on the training data but the performance drops significantly over the test it is called the overfitting model or Memorizing model. If the model is not learning and consistently performing poorly over the test and the train set then it is called the underfitting model. When a model shows almost equal results over both train and test set it is called best fit model.
Why Did the Decision Tree Overfit While the Linear Model Didn’t?
The primary reason for this difference lies in the nature of the models:
- Linear models are parametric models, meaning they have a fixed and finite set of parameters to learn from the data.
- Decision trees are non-parametric models, meaning they continue learning from the data until no further patterns remain.
Visualizing Overfitting with Graphviz
To understand the depth and complexity of our decision tree, we can use the Graphviz module in Python to visualize its structure.
Visualization
Step 1: Generating the Tree Structure
- First, we generate the tree structure using the classifier instance.
- We use the
export_graphvizfunction to create an intermediary file containing information about the nodes and edges of the tree.
Step 2: Creating a Visual Representation
- Using the Graphviz module, we convert this file into a PNG image.
- This process creates a tree visualization that can be easily analyzed.
Understanding the Output
- The full decision tree is extremely large and difficult to interpret without zooming in.
- By analyzing the leaf nodes, we can conclude that the tree memorizes the dataset, leading to an overfitted model.
from sklearn.tree import export_graphviz
export_graphviz(decision_tree=classifier,
out_file='tree_viz',
max_depth=None,
feature_names=X.columns,
label=None, impurity=False)
from graphviz import render
render(filepath='tree_viz',
format='png',
engine='neato')
tree_viz.png

HyperParameter Tuning
These methods are used to prevent overfitting in decision trees. Pruning is the technique of preventing a decision tree from overfitting by tuning its characteristics To analyse the effect of different hyperparameter of decision tree on the train-test score we created two function as shown in figure. The effect function plots the curve between train and test score.
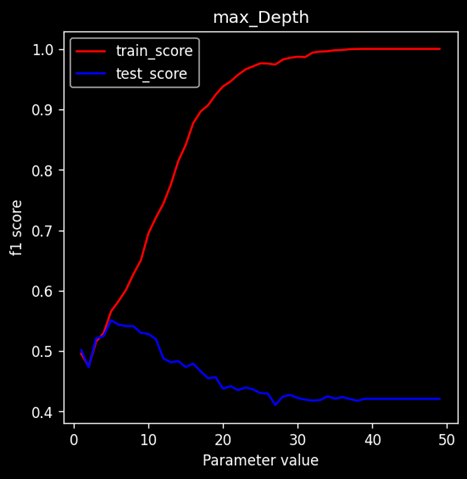
Max Depth
On applying the score-effect function we created on the max-depth parameter of decision tree we can see that: As max depth increases the train score increases significantly but the test score on other hand decreases with it. Note that the train and test score both increased together till a point. After that point, we can say the tree started overfitting which led to the drastic decrease of train score and increase of train score.
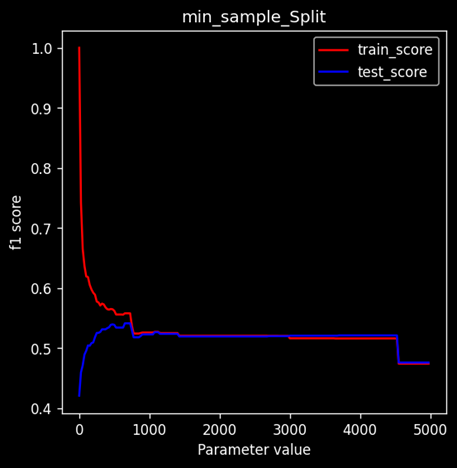
Min Sample Split
Min-sample-split tell the decision tree what is the minimum number of required observation in any given node in order to split it. (default = 2) For small parameters train and test score have large variation. For large values train and test score match accordingly. For very large values there is a dip for both train and test score which led to underfitting of data. Optimal range: 950-1000.

Max Leaf
Max leaf nodes specifies maximum terminal nodes allowed. For very low values tree is underfitting. For very high values tree is overfitting. According to this plot overfitting starts after 25.
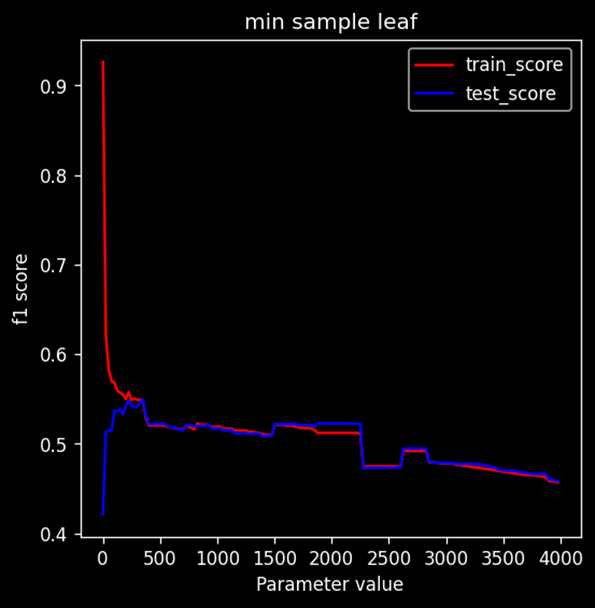
Min Sample Leaf
Min-sample-leaf denotes the minimum number of sample points to be present for splitting. Clearly as values keep on increasing the model escapes overfitting for a small range of values after which it starts to underfit.
Macro parameters like max-depth prevents tree from growing on a macro level and other three parameters fine tune the decision tree on micro level. So, a good practice is to first find the best range for the tree on a macro level so that tree do not overfit and after that fine tune the other three parameters.