Links & Overview
-
PDF NOTES Download PDF
- Access the GitHub repository for all my Jupyter notebooks
- Kaggle Notebook Link for Project 1: Housing Data Set Regression Modelling
- Kaggle Notebook Link for Project 2: Population Demography
Getting started with MACHINE LEARNING
What is Machine Learning
Machine learning is the ability of machines, that is, computers to learn and improve from their past experiences or data, without being explicitly programmed.
Machine learning is the ability of machines, i.e., computers or ideally computer programs, to learn from the past behaviour or data and to predict the future outcomes without being explicitly programmed to do so.

Machine learning algorithms are constantly analysing the world-wide data and using them to learn and give better predictions.
How Machine Learning works
Machine learning is the ability of machines to learn from past experiences. The past experiences are called Data. Data is any kind of information and can be represented in any form like images, pdfs, location, chats or documents etc.Data collection has risen exponentially in past few decades. All this data is stored and used in ML models for better functioning.
EXAMPLE PROBLEM1: Given a bank and a customer associated with bank who wants a loan, how will an ML model predict whether to give loan to the customer or not.
The given ML model, say M, will analyse the past data of all the customers who were given a loan and will classify the set of customers in two category, Good Customer and Bad Customer.
- Good Customer: Any customer who repaid the loan on time
- Bad Customer: Any customer who didn’t repaid the loan on time.

Now M will use the previous data and identify a pattern between good and bad customers and then will use it to place the new customer into one of the classifications. Hence the model will predict whether the customer should begiven a loan or not on basis of if he/she can repay the loan or not. Hence in total we can say that ML model analyses past data and derives patterns and insights from it and then applies this intelligence on a new piece of data to predict or recommend actions.
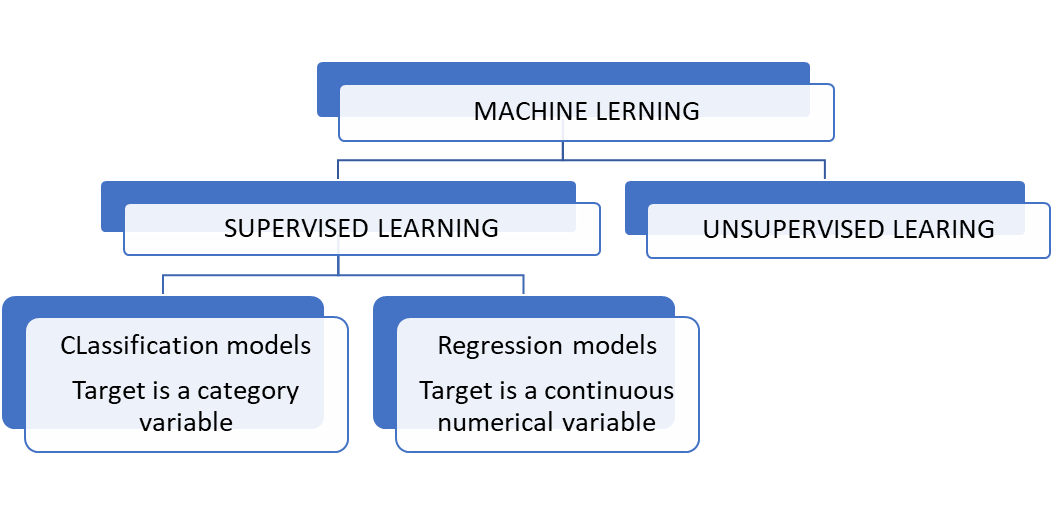
Types of Machine Learning
Data is a collection of information about something.The data which contains a target variable or an output variable that answers a question of interest is called Labelled Data.
Example: Data of patients suffering from a particular disease.
Data stored can be: Name, age, gender, location, Blood type. Weight, height, mean body temperature etc.
Then we can additionally store a TARGET or Category variable “Was patient completely cured or not after the treatment”. The answer to this question can be YES or NO. This target variable is also called Dependent variable as it can depend on other variables listed above. The other data are called as Independent Variables. If the data given just contains independent data and do not have a predefined target variable or category variable then the dataset is referred to as Unlabelled Data.
SUPERVISED LEARNING
- In supervised learning model the ML model learn under supervision, and this supervision is provided by independent variables and the target variable (or collectively Labelled data).
- The model learns from the Past labelled data and the process is called Training the data. Once the model is trained, we can feed new unlabelled data to it to predict target variable.
- There is a target variable involved.
- Works only on labelled data.
- Most of ML models used in present date are supervised learning due to high availability of data around us.

UNSUPERVISED LEARNING
- The machine learning that is deployed to find patterns in unlabelled data is called unsupervised learning.
- Complement of supervised learning.
- There is no target variable involved.
- Works only on unlabelled data.
- This type of model only detects if there is some pattern present in the data or not.
- Since there is no target variable present, the data on which unsupervised learning operates is called Unlabelled data.
Types of data
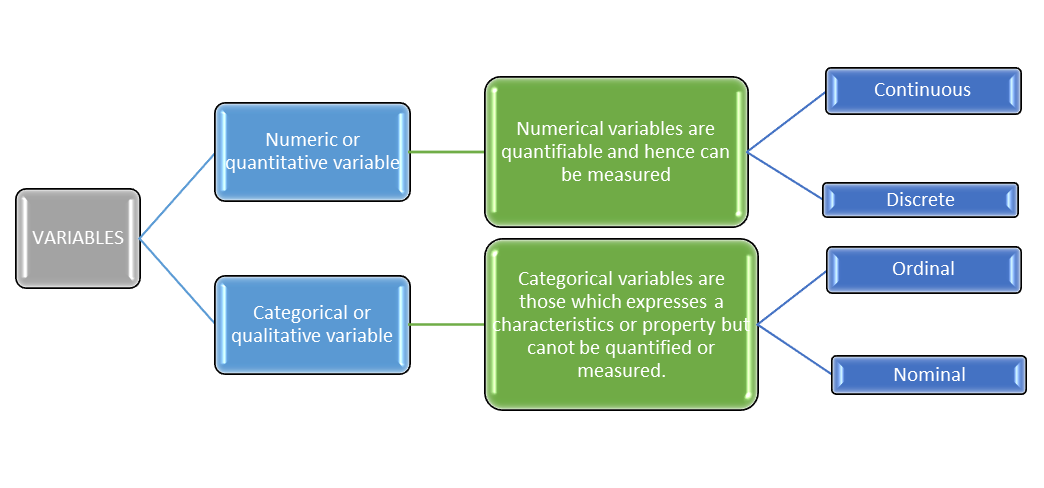
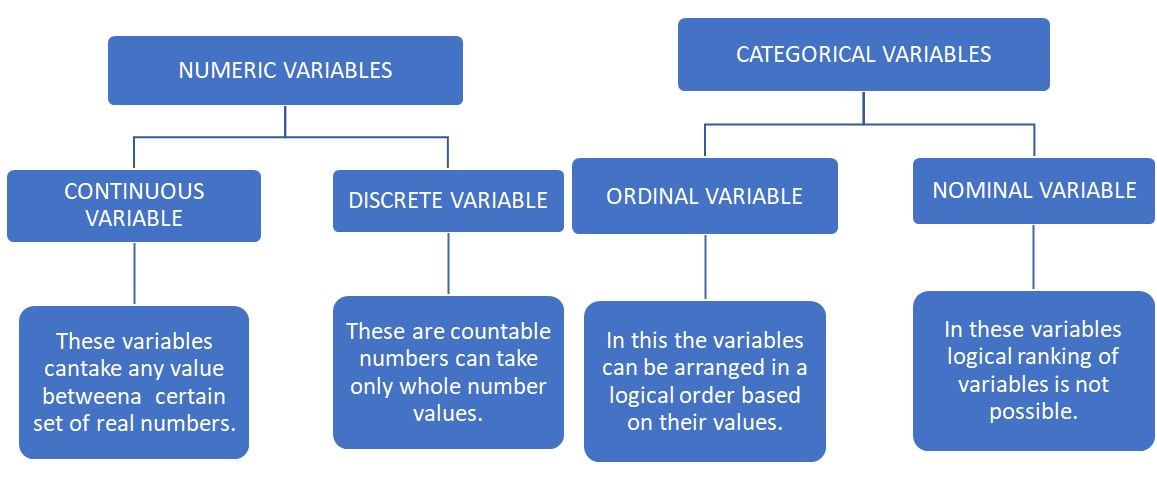
Data is information about something. A variable represents one specific characteristics of the data or tells one specific information about the data under consideration. A value of variable can change for different data points or over time.
Example taking about price of mobile phones, if we present the exact price then it is a numeric variable but if we categorize the price in, say cheap and expensive, then this type of data will be called as categorical variable.
Independent variables are the one whose value don’t depend on any other
variables.
Dependent variables are those whose values depend on other independent
variables and
cannot be changed easily.
Structured variables always have a structure or format when they are
stored.
Common structures are tabular format of data organization.
Unstructured Data have no structure available for the data and no tabular
format is present.
This type of data is human readable but machines cannot directly read these kinds of data.
Example of this data type are images, audio etc.
For machines to understand this type of data the unstructured data is converted to
structured data (usually in form of matrix) and then is read and used in proposed ML model.